


2月12日,智谱AI正式发布并开源全新一代旗舰大模型GLM-5。作为国内唯一掌握TPU架构高性能AI芯片核心技术并实现量产的企业,中昊芯英同日完成对GLM-5的Day0推理适配。
凭借自研TPU芯片“刹那®”高带宽近存架构与高效张量计算核心的AI原生架构优势,GLM-5已在中昊芯英计算平台上实现高吞吐、低延迟的稳定运行。这不仅是双方生态合作的里程碑,更是专用算力芯片(TPU)在复杂工程化场景(Coding&Agent)中性能优势的集中体现。
GLM-5:Agentic Engineering时代最好的开源模型
GLM-5是智谱AI推出的全新基座模型,在真实编程场景体感逼近ClaudeOpus4.5。其参数规模扩展至744B,首次集成稀疏注意力机制,是目前开源领域最强的Coding与Agent模型之一。
在全球权威的ArtificialAnalysis榜单中,GLM-5位居全球第四、开源第一。
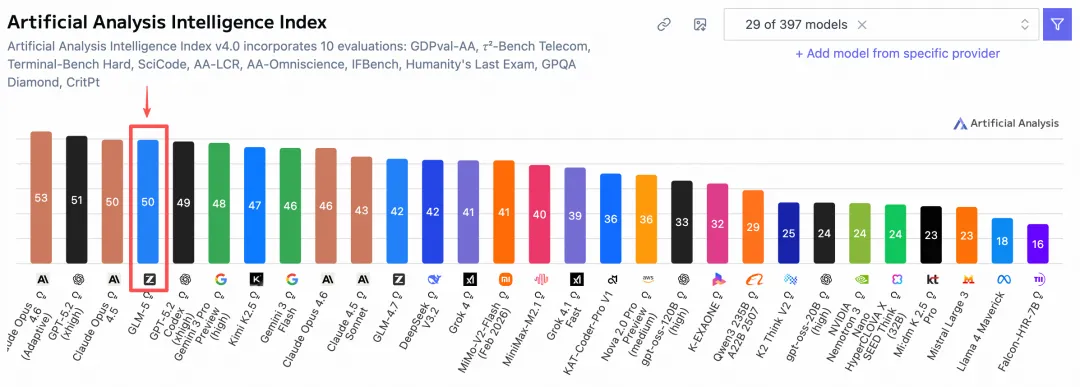
(GLM-5在Artificial Analysis榜单全球排名第四、开源第一)
GLM-5在众多学术基准测试中相比GLM-4.7取得了显著提升,并在推理、编码和智能体任务上取得了全球所有开源模型中的最佳性能,缩小了与前沿模型的差距。
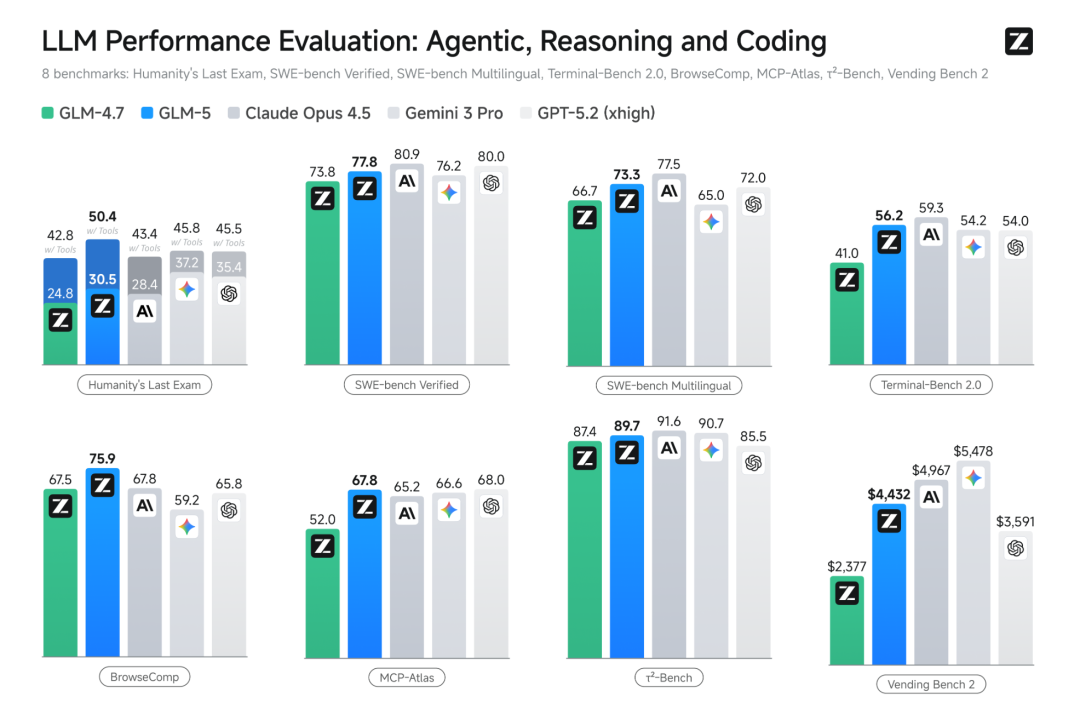
(GLM-5的众多学术基准测试情况)
Day 0适配之路:TPU赋能Coding与Agent规模化落地
“刹那®”TPU架构高性能AI专用算力芯片,由中昊芯英历时近5年100%自研,拥有完全自主可控的IP核、全自研指令集与计算平台。在AI大模型计算场景中,算力性能超越海外著名GPU产品近1.5倍,能耗降低30%。同时,通过采用Chiplet技术与2.5D封装,实现了同等制程工艺下的性能跃升,并支持1024片芯片片间互联,实现千卡集群线性扩容,支撑超千亿参数大模型运算需求。

(中昊芯英TPU架构高性能AI专用算力芯片)
中昊芯英对GLM全系列模型保持着长期的深度跟踪与适配优化。在此前GLM-4.5&4.7的适配过程中,中昊芯英研发团队基于“刹那®”TPU的近存架构与高效张量核心,完成了芯片与GLM系列模型架构的深度融合,实现了GLM-4.5&4.7在TPU集群上推理吞吐量的显著提升,更为此次GLM-5的Day0高效适配积累了丰富的底层算子库与工程经验。
TPU架构专为AI/ML而生,通过优化计算单元的维度和数据传输的路径,在大模型推理/训练等特定计算范式下,TPU比传统GPU架构能实现更高的能效比和计算密度。在长期以来与GLM系列模型的适配中,“刹那®”芯片的可重构多级存储、近存运算设计以及流水线式的时空映射,有效提升了GLM大模型计算速度和精度,为模型在复杂任务中的运行提供了高效支持。
依托自研GPTPU软件栈,中昊芯英“刹那®”TPU原生适配PyTorch、vLLM、DeepSpeed、Megatron-LM及SGLang等主流深度学习框架与推理引擎,助力用户实现算法的“零成本”跨平台迁移。无论是构建支持1024片芯片片间互联的“泰则®”大规模计算集群,还是部署面向Coding&Agent场景的高并发、低延迟在线推理服务,中昊芯英均展现出对标主流专用算力产品的卓越能效与稳定性,旨在为AIGC时代筑牢坚实、易用的国产专用算力底座。
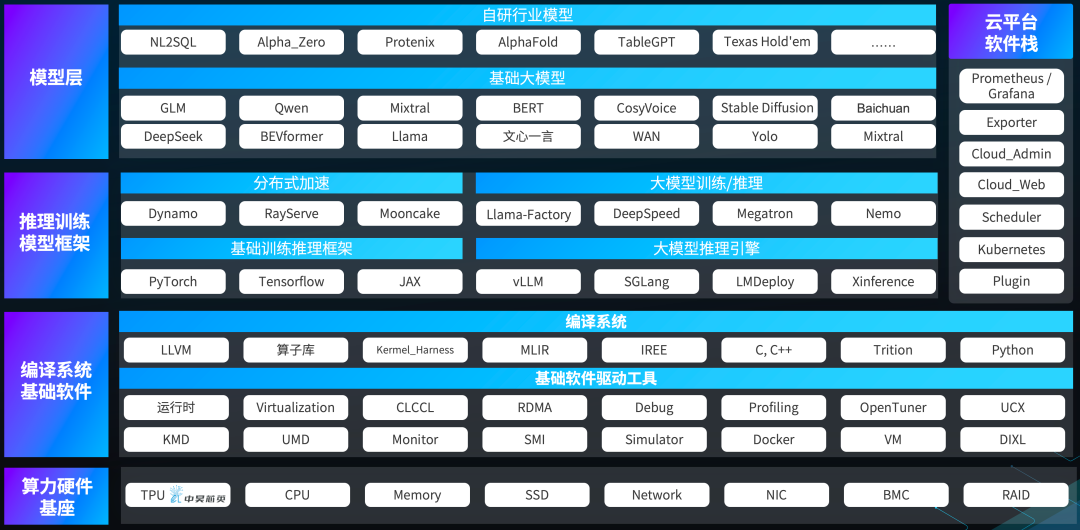
(中昊芯英TPU芯片AI软件栈)
从计算单元到集群:软硬件协同与核心技术突破
GLM-5拥有高达744B的超大规模参数并首次集成稀疏注意力机制,对底层算力的并发性、通信带宽及指令调度提出了极高的要求。中昊芯英从计算、通信、调度三层面的技术突破,系统性构筑了从单芯片到千卡集群的软硬一体高效计算底座:
·算力协同优化:攻克稀疏计算瓶颈
针对GLM-5稠密计算与稀疏激活交错并存的MoE特性,中昊芯英采用了面向稀疏计算的算力协同优化架构,在提升算力利用率的同时,确保了模型在处理复杂Coding任务时的训练吞吐率与收敛效率。
·自适应片上网络:打通大模型负载通信高速路
大模型推理的延迟往往受限于片上通信。中昊芯英通过自适应片上网络通信架构,引入动态低延迟路由算法与网络状态感知机制,有效解决了大模型负载下的通信效率瓶颈。这使得“刹那®”芯片在驱动GLM-5执行长程Agent任务时,能够保持极高的链路利用率与通信稳定性。
·分布式执行环境:实现多级并行的高效调度
为了让GLM-5在服务器集群上实现线性扩容,中昊芯英构建了面向AI指令体系的分布式编译及执行环境。该技术支持节点间、设备内及指令级的多层次并行调度,通过融合静态图稳定性与动态图灵活性的混合建图策略,为GLM-5形成了端到端的高效执行路径,确保了模型在异构平台上的原生高效运行。
GLM-5擅长处理复杂系统工程与长程Agent任务,中昊芯英的TPU AI芯片与计算平台为其提供了坚实的算力底座。通过“自研TPU芯片+超算集群+顶级大模型”的深度融合,双方将共同为客户提供极具竞争力的AI软硬件解决方案。
中昊芯英“刹那®”TPU AI芯片对GLM-5的Day0适配,再次印证了TPU芯片“ForAI”的专用架构在AIGC时代的先进性。未来,中昊芯英将继续坚定TPU技术路径,聚焦AI计算本质,并通过深化与智谱AI等顶尖合作伙伴的生态共建,为全球客户提供具备生产力变革能力的AI创新方案。
来源:界面新闻
ㅤ
ㅤ
▲免责声明:此文内容为本网站转载企业宣传资讯,仅代表作者个人观点,与本网无关。所涉内容不构成投资、消费建议,仅供读者参考,并请自行核实相关内容。



































